任务队列的应用场景
考虑如下场景:
1.社交网站某用户发布了一组照片,这条新鲜事需要适时地推送给该用户的所有好友。如果好友数量很多的话,在同一时刻有很多的推送任务要处理,如果同步操作的话会造成阻塞。而且一个社交网站有大量用户,同时进行推送会给服务器造成很大压力。所以,处于用户体验考虑,用户发布照片这个操作需要在较短时间得到反馈。
2.在文献搜索系统的主页,用户可以查到当前一小时最热门的十篇文献,并能够直接访问该文献。文献系统所管理的文献非常多,出于用户体验考虑,用户获得十大热门文献这个操作也要在较短时间内得到反馈。
考虑到大并发的web系统,对于上面两种场景的需求,如果在请求处理周期内完成这些任务,再将结果返回,这种传统的做法会导致用户等待的时间过长,同时web后台对任务的处理能力也缺乏扩展性。
对于这种场景,任务队列是最有效的解决方案。任务队列一般采用生产-消费模型,包括生产者、任务处理中间方、任务消费者。任务生产者负责生产任务,中间方负责接收任务生产者的任务处理请求,对任务进行调度,并将任务发送给消费者来处理。
Celery: 基于 Python 的开源分布式任务调度模块
Celery是一个用python编写的分布式的任务调度模块,它有着简明的 API,并且有丰富的扩展性,适合用于构建分布式的 Web 服务。
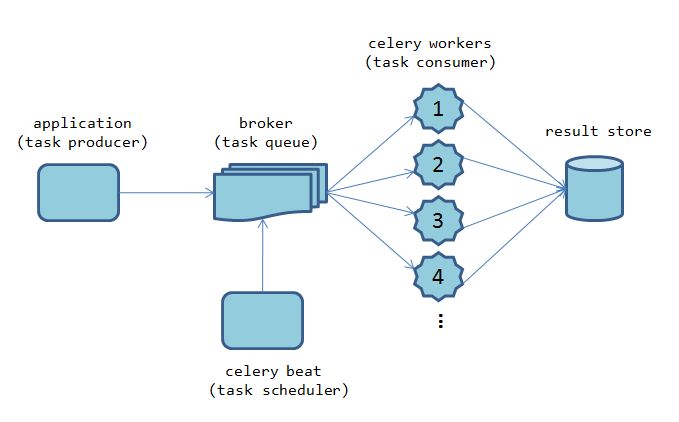
Celery 的模块架构较为简洁,但是提供了较为完整的功能:
任务生产者 (task producer)
任务生产者 (task producer) 负责产生计算任务,交给任务队列去处理。在 Celery 里,一段独立的 Python 代码、一段嵌入在 Django Web 服务里的一段请求处理逻辑,只要是调用了 Celery 提供的 API,产生任务并交给任务队列处理的,我们都可以称之为任务生产者。
任务调度器 (celery beat)
Celery beat 是一个任务调度器,它以独立进程的形式存在。Celery beat 进程会读取配置文件的内容,周期性地将执行任务的请求发送给任务队列。Celery beat 是 Celery 系统自带的任务生产者。系统管理员可以选择关闭或者开启 Celery beat。同时在一个 Celery 系统中,只能存在一个 Celery beat 调度器。
任务代理 (broker)
任务代理方负责接受任务生产者发送过来的任务处理消息,存进队列之后再进行调度,分发给任务消费方 (celery worker)。因为任务处理是基于 message(消息) 的,所以我们一般选择 RabbitMQ、Redis 等消息队列或者数据库作为 Celery 的 message broker。
任务消费方 (celery worker)
Celery worker 就是执行任务的一方,它负责接收任务处理中间方发来的任务处理请求,完成这些任务,并且返回任务处理的结果。Celery worker 对应的就是操作系统中的一个进程。Celery 支持分布式部署和横向扩展,我们可以在多个节点增加 Celery worker 的数量来增加系统的高可用性。在分布式系统中,我们也可以在不同节点上分配执行不同任务的 Celery worker 来达到模块化的目的。
结果保存
Celery 支持任务处理完后将状态信息和结果的保存,以供查询。Celery 内置支持 rpc, Django ORM,Redis,RabbitMQ 等方式来保存任务处理后的状态信息。
安装Celery和RabbitMQ
极为简单:
pip install celery
yum -y install rabbitmq-server
Celery需要一个消息代理人(broker)来处理请求,分发任务。我们使用rabbitmq来做这个broker。一般安装完rabbitmq就会自动启动,没有启动的话,可以用systemctl start rabbitmq-server来启动。
使用Celery
创建一个celery实例
创建一个tasks.py文件,引入celery并实例化:
from celery import Celery
from time import sleep
app = Celery('tasks', backend='amqp', broker='amqp://')
第一个参数会添加到任务上用来区分它们。backend参数是可选的,如果想要查询任务状态或者任务执行结果时必填。broker参数表示用来连接broker的URL,rabbitmq采用的是一种称为’amqp’的协议,如果rabbitmq运行在默认设置下,celery不需要其他信息,只要amqp://即可。
创建Celery任务
在tasks.py中继续添加如下代码:
@app.task(ignore_result=True) #这个hello函数不需要返回有用信息,设置ignore_rsult可以忽略任务结果
def hello():
print 'Hello,Celery!'
@app.task
def add(x,y):
sleep(5) #模拟耗时操作
return x+y
启动celery worker进程
在终端中执行
celery -A tasks worker --loglevel=info
或
celery -A tasks worker & #后台执行
使用队列处理任务
打开python命令行,导入任务函数:
from tasks import hello, add
hello() #正常执行,没有被worker处理
add() #正常执行,没有被worker处理
hello.delay() #交给worker处理
res = add.delay(3,4) #交给worker处理
查看任务是否执行完,可以用ready()方法res.ready(),获取返回值可以使用get()方法,res.get()。
使用配置文件
对于简单的应用来说,可以直接在tasks文件中通过app = Celery(...)的方式来实例化。
当然,创建了Celery实例之后,也可以修改配置:
单个:
app.conf.CELERY_TASK_SERIALIZER = 'json'
或批量(支持dict语法):
app.conf.update(
BROKER_URL = 'amqp://',
CELERY_RESULT_BACKEND = 'amqp://',
CELERY_TASK_SERIALIZER = 'json',
CELERY_ACCEPT_CONTENT = ['json'],
CELERY_RESULT_SERIALIZER = 'json',
CELERY_TIMEZONE = 'Asia/Shanghai',
CELERY_ENABLE_UTC = True
)
但是对于大的项目不推荐这种硬编码的方式,最好将Celery的配置保存在一个配置文件中,便于集中管理和使用。
新建一个配置文件celeryconfig.py,写入配置内容:
BROKER_URL = 'amqp://'
CELERY_RESULT_BACKEND = 'amqp://'
CELERY_TASK_SERIALIZER = 'json'
CELERY_ACCEPT_CONTENT = ['json']
CELERY_RESULT_SERIALIZER = 'json'
CELERY_TIMEZONE = 'Asia/Shanghai'
CELERY_ENABLE_UTC = True
CELERY_IMPORTS = ("tasks",)
然后在tasks文件中app.config_from_object('celeryconfig')。